
What Is Tag Piggybacking and How Does It Create Privacy Compliance Risk?
By Vault JS | December 23, 2022
Key Takeaways
- Tag piggybacking occurs when one JavaScript tag on your site loads another through server redirects, creating daisy chains of third-party data access that the site owner never approved. A single container tag can trigger a sequence of redirects that grants dozens of vendors access to collected user data, and these chains change constantly, making manual oversight impractical.
- Piggybacked tags enable vendors to de-anonymize user data by synchronizing records across databases. When two vendors exchange data about the same user through redirect chains, they can match anonymous records across their separate systems, merge profiles, and build more complete user identities, all without the website owner’s knowledge or the user’s consent.
- Tag management systems and one-time audits are insufficient to control piggybacking risk. Most TMSs are not built to detect chains of server redirects or compromised iframes loading unauthorized code. Because enterprise sites can see thousands of tag changes per month, only continuous monitoring can distinguish legitimate changes from emerging data leaks or unauthorized third-party access.
Your enterprise website is connected to a massive, constantly changing, interconnected, and partially hidden ecosystem of JavaScript tags. Often piggybacked to each other, these tags enable the various technology tools used on your site. Unfortunately, the system also creates serious risks of data being shared with unwanted parties or de-anonymized without permission, and all without your knowledge. Here we’ll review the problem and outline the solution.
What is Tag Piggybacking?
A tag is a small piece of code executed by a website to collect data — for site analysis, to refine digital marketing strategies, or to pass on data to a third-party vendor. Piggybacking occurs when one tag on the page loads another through what is called a server redirect.
When a tag redirects a server request, both the request itself and the data associated with it are forwarded along to a new target. This target, often a third-party tag, can then load more tags itself, or it can pass the request back to be forwarded elsewhere. This can begin a long daisy chain of redirected requests and linked tags that are all granted access to the data collected by the single original container tag.
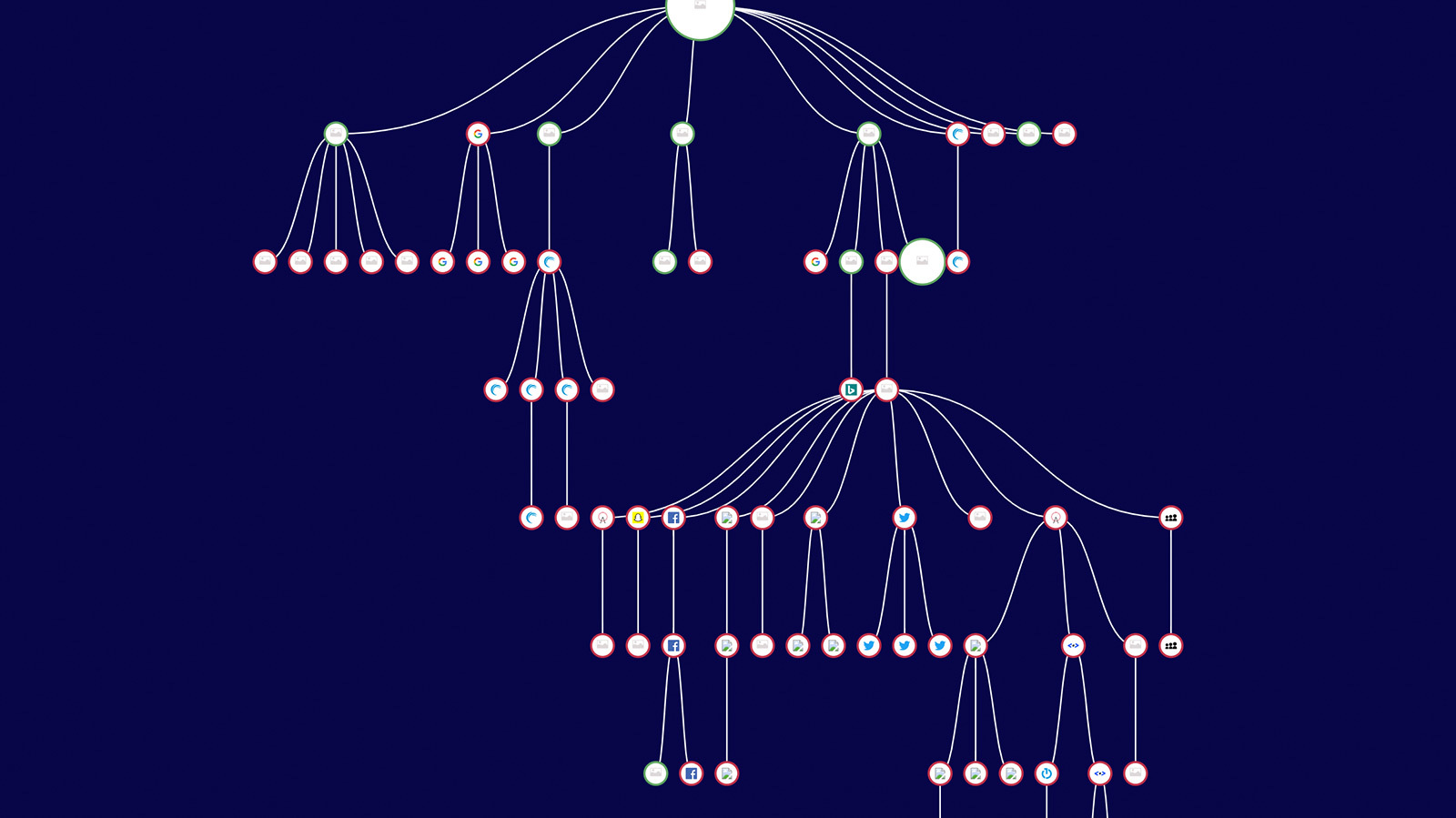
An example of a daisy chain can be seen in this analysis of one webpage’s tag ecosystem. The webpage is represented by the large circle at the top. The smaller circles represent tags, each called by either the webpage itself or by earlier tags. In the long vertical string, you will see a series of redirects between different third-party vendors. In other words, you’re seeing tag piggybacking in action.

How Does Tag Piggybacking Create Privacy and Security Risk?
Piggybacking can be an efficient strategy to increase data distribution to third parties. Forwarding data down a chain means that there are fewer data collection operations than if each tag were linked independently, and the site is not forced to load as much code directly. The page can operate more quickly and with fewer opportunities for error. The vendors who control the tags can still access relevant information while site users have a better experience.
The problem arises from an issue of scale and a lack of transparency. Uncontrolled chains of tags can grow to be indefinitely long, clogging up the page with unnecessary redirections and outside parties that the host web page never called for or approved. These additional operations can slow site performance and potentially result in the loss of data.
Moreover, as the chains of redirects are constantly changing, it can be difficult to tell what third parties are being granted access to what data. It can be even more difficult to limit that data flow. Unwanted actors can slip in and access the information that an earlier tag collected. These breaches will typically go undetected, lost in the confusion of linked and nested tags. Piggybacked chains are a security threat for your site and your customers, and they mean you cannot guarantee your site is complying with data protection laws.
Beyond lost or misappropriated data, tag piggybacking opens opportunities for vendors to de-anonymize data. This can be accomplished through the synchronization of user databases. When two vendors pass data about a single user back and forth, they can identify commonalities between two anonymous records in their two separate databases. The vendors can, for instance, prove that Record #123 in database A refers to the same user as Record #456 in database B, and they can go on to merge those records and pool their data. Each vendor now has more information about the user than it could collect on its own, and your customer’s anonymity has been compromised.
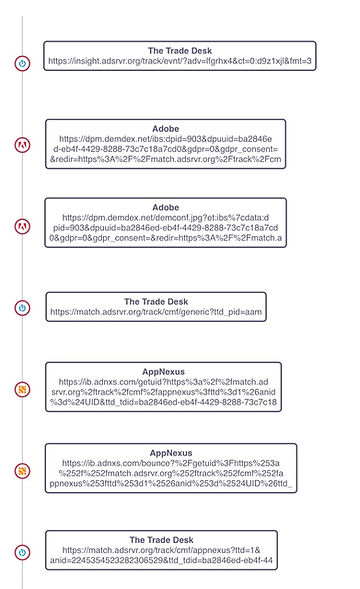
In the example above, the longest chain of redirects includes several such back-and-forth exchanges between a digital marketing service and various outside vendors, all of which occurred without the permission of the host web page, and all of which pose a security risk. A close-up is visible here.
In this portion of the tag tree, The Trade Desk (the marketing service) can be seen redirecting a server request and user data to Adobe. Adobe passes the request back, only for The Trade Desk to forward the same data on to AppNexus and beyond.
The Adobe and AppNexus tags were not called by the site itself, and these two vendors would not typically have access to this site’s data. They have gained access through server redirects and tag piggybacking.
Can Tag Management Systems Detect Piggybacking?
In the earlier days of the internet, an average webpage may have only loaded three or four tags to operate. Nowadays, that number is closer to 90. When your website has hundreds or thousands of pages, and when tags are constantly added or removed from your site, it’s impossible to keep track of everything manually.
The site management tools pre-built within most developer platforms allow for some insight into what tags are being called, but they have not all been built with tag piggybacking or human managers in mind. These tools may fail to notice linked tags. Plus, they’re unable to identify how tags gained access to your site. Finally, they can overwhelm you with a flood of unnecessary information.
Even dedicated Tag Management Systems (TMSs) have shortcomings. Many are not focused on security, and many are unable to protect your site if a trusted third party is attacked. For instance, if your site contains an iframe that embeds content from a media hosting platform, and that hosting platform is compromised, the iframe can load unwanted code or dangerous chains of piggybacked tags. Basic TMSs will not detect these types of security breaches.
Individual audits of your site’s tag infrastructure can help provide a snapshot of current operations and security threats, but they will be unable to detect emerging threats as the tags change. A site’s tags may see thousands of changes in a month, and while most will be minor and harmless, all will carry the potential for new data leaks. In such a dynamic environment, the lack of flexibility in fixed audits represents a real shortcoming.
Ideally, your security solution would be able to monitor your site continuously, analyzing code changes to distinguish those that pose legitimate threats from the innocuous masses. This site monitoring should include identifying where benign tag piggybacking has gotten out of control. An effective solution will also be able to track the origins of piggybacked tags to see what parties may have granted them access to the site. Finally, it will provide a user-friendly interface that alerts site managers if and only if they need to be concerned.
How Do You Monitor Tag Piggybacking Continuously?
A robust digital marketing assurance platform will use a combination of artificial intelligence and human oversight to balance thoroughness with ease of use.
An AI-based tool, unlike a human, is able to constantly monitor all requests sent to and from a web page — plus all code operating on the page. No small feat for an enterprise with 1,000s of pages across a given domain. In doing so, it can detect and analyze new, changed or malicious code. Monitoring each step enables the system to identify many types of security risks. For example, one token being passed back and forth between different vendors can indicate dangerous tag piggybacking and record synchronization. Each step may be harmless by itself, but by monitoring the whole system, a potentially dangerous sequence can be uncovered. An AI system can also move beyond a reliance on static rules and whitelists to recognize these concerning actions. Instead, it can evolve alongside the threats it faces, protecting your site from unknown as well as established dangers.
The massive, dynamic, and hidden tag ecosystem connected to your site, complicated by tag piggybacking, is an urgent risk to be managed. A digital marketing assurance platform makes this possible. To learn more about data assurance, and to get a free audit of your own tag ecosystem, contact Vault JS today.
Recent Posts
Cookie Compliance in 2026: Why Consent Banners Don’t Prevent Enforcement Actions
Consent banners alone do not guarantee cookie compliance. Regulators now focus on actual third-party data flows, tracking pixels, cookie syncing, fingerprinting, and unauthorized data sharing....
Read More

The Privacy Laws That Can Send Executives to Prison
Executives face criminal liability under global privacy laws, including prison sentences in the U.S., EU, and beyond. This guide breaks down where the risk exists...
Read More

Server-Side Fingerprinting Explained: How Tracking Works Without Cookies
Server-side fingerprinting links user sessions even when browser signals change. This post explains how it works, why traditional defenses fail, and the risks it creates...
Read More